How to Write a Lisp Interpreter in JavaScript
- Published on
In a previous essay series, we saw how to write an expression evaluator that supports arithmetic and logical operators, variables, and functions like IF, MIN, and MAX. In this essay, we'll implement a similar but slightly more advanced program: an interpreter for a dialect of Lisp called Scheme.[1]
We'll start with a brief discussion about Scheme's syntax and the basic architecture of the interpreter. Then we'll implement number, boolean, string, and list data types; primitive procedures; conditional expressions; variables; and lambdas.
Hopefully, you'll have learned about some basic concepts behind languages and interpreters by the end of the essay.
A quick introduction to Scheme
Scheme is a minimalist dialect of Lisp, a family of languages based on a nested-list notation called the symbolic expression (or s-expression).
An expression can either be an atom: a number (e.g. 8), a string (e.g. "welcome"), a symbol (e.g. count); or a list expression: a "(", followed by zero or more expressions, followed by a ")". A list expression starting with a keyword (e.g. (if ...) or (define ...)) is a special form, while one starting with a non-keyword is a function call (e.g. (fn ...)).
All Scheme programs consist entirely of these expressions. Unlike languages like Java, C, and Python, Scheme makes no distinction between statements and expressions.
10 ; 10
(+ 137 349) ; 486
(define factorial
(lambda (n)
(if (<= n 1) 1 (* n (factorial (- n 1))))))
(factorial 10) ; 3628800The basic architecture of the interpreter
A Scheme interpreter accepts a Scheme program's source code, evaluates the program's expressions, and returns the final result.
We may split the interpreter into three main components: a scanner, a parser, and an interpreter.
Scanner → Parser → Interpreter
The scanner walks through the source code and extracts the meaningful "units", or tokens, into a list. It discards unneeded whitespace characters and reports errors when it finds unknown characters.
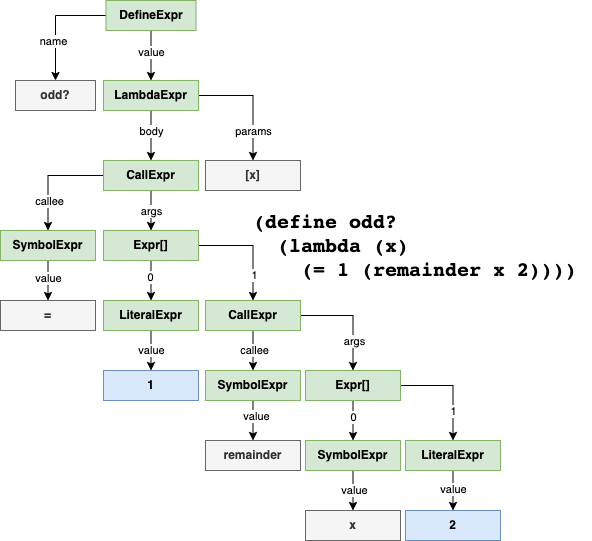
scan(`(define odd?
(lambda (x)
(= 1 (remainder x 2))))`);
// ["(", "define", "odd?", "(", "lambda", "(", ...]The parser then transforms the list of tokens into an Abstract Syntax Tree (AST) that represents the syntactic structure of the program.
Each node in the AST describes some syntactic component in the program. A LiteralExpr node holds a literal value, like a number or a string; a CallExpr node represents a function call, and so on.
Finally, the interpreter evaluates the AST. It walks from the top of the tree to the bottom, evaluates each node, performs any needed side-effects (like defining or modifying variables), and returns the final result.
We may define a run function to perform all three steps of the evaluation:
const interpreter = new Interpreter();
function run(source) {
const scanner = new Scanner(source);
const tokens = scanner.scan();
const parser = new Parser(tokens);
const expressions = parser.parse();
return interpreter.interpretAll(expressions);
}Lisp calculator
We'll begin by implementing the interpreter as a simple "calculator". Like a regular calculator, it will be able to perform basic arithmetic operations on numbers. But it will also support boolean, string, and list operations. When this version is complete, we'll add variables and program-defined procedures.
The syntax for the first set of supported expressions is as follows:
| Expression | Syntax | Semantics and examples |
|---|---|---|
| symbol | symbol | A symbol is interpreted as a variable name; its value is the variable's value. The interpreter doesn't yet support defining new variables, so the only known symbols are the primitive procedures. Examples: + => PrimitiveProcedure, cons => PrimitiveProcedure. |
| constant literal | number | string | boolean | Numbers, strings, and booleans evaluate to themselves. Examples: 3 => 3, #t => #t |
| conditional | (if test consequent alternative) | Evaluate test; if "truthy" (i.e. any value other than #f), evaluate and return consequent; else, evaluate and return alternative. Example: (if (< 2 3) 4 5) => 4 |
| procedure call | (proc arg...) | If proc is not a keyword, it is treated as a procedure. Evaluate proc and all the args, then call the procedure with the arguments. Example: (remainder 5 2) => 1 |
Scanner
Before setting up the scanner, we'll define a Token class and the expected token types.
const TokenType = {
LeftBracket: 'LeftBracket',
RightBracket: 'RightBracket',
Symbol: 'Symbol',
Number: 'Number',
Boolean: 'Boolean',
String: 'String',
Eof: 'Eof'
};
class Token {
constructor(tokenType, lexeme, literal) { ... }
}The lexeme of a token is its string representation as it appears in the source program, e.g. "if", "string-append", "sum". The literal is the, er, literal value of the token, e.g. true and false for booleans, 3 for the number 3.[2]
In the Scanner class, we'll define a scan method that returns a list of tokens from a program source.
class Scanner {
start = 0;
current = 0;
tokens = [];
constructor(source) {
this.source = source;
}
scan() {
while (!this.isAtEnd()) {
// save the index at the start of each new token
this.start = this.current;
const char = this.advance();
switch (char) {
case '(':
this.addToken(TokenType.LeftBracket);
break;
case ')':
this.addToken(TokenType.RightBracket);
break;
case ' ':
case '\r':
case '\t':
case '\n':
break;
// ...
}
}
this.tokens.push(new Token(TokenType.Eof, '', null));
return this.tokens;
}
isAtEnd() { return this.current >= this.source.length; }
advance() { return this.source[this.current++]; }
peek() { return this.source[this.current]; }
addToken(tokenType, literal) {
const lexeme = this.source.slice(this.start, this.current);
this.tokens.push(new Token(tokenType, lexeme, literal));
}
}We advance through each character in the source string, looking for tokens. We add tokens for left and right brackets and skip over whitespace characters. After scanning the entire source, we push an Eof token and return the list. (We'll use the Eof token later in the parser to check for the end of the token list.)
We also need to scan for boolean values: #t and #f, representing true and false respectively. Inside the switch block in scan:
case '#':
if (this.peek() === 't') {
this.advance();
this.addToken(TokenType.Boolean, true);
break;
}
if (this.peek() === 'f') {
this.advance();
this.addToken(TokenType.Boolean, false);
break;
}To scan string tokens, we check for a double-quote and advance till we find a closing double-quote. The string value will be the text between the start and current indexes.
case '"':
while (this.peek() !== '"' && !this.isAtEnd()) {
this.advance();
}
const literal = this.source.slice(this.start + 1, this.current);
this.addToken(TokenType.String, literal);
this.advance();
break;In the default case of the switch block, we'll scan for numbers and symbols. If the current character is a digit, we'll advance till the end of the number, parse it as a JavaScript float, and push the token to the list.
default:
if (this.isDigit(char)) {
while (this.isDigitOrDot(this.peek())) {
this.advance();
}
const numberAsString = this.source.slice(this.start, this.current);
const literal = parseFloat(numberAsString);
this.addToken(TokenType.Number, literal);
break;
}
// isDigit(char) { return char >= '0' && char <= '9'; }
// isDigitOrDot(char) { return this.isDigit(char) || char === '.'; }Similarly, if the current character is valid for an identifier, we'll advance till the end of the identifier, and then add a Symbol token.
if (this.isIdentifier(char)) {
while (this.isIdentifier(this.peek())) {
this.advance();
}
this.addToken(TokenType.Symbol);
break;
}
/*
isIdentifier(char) {
return (
this.isDigitOrDot(char) ||
(char >= 'A' && char <= 'Z') ||
(char >= 'a' && char <= 'z') ||
['+', '-', '.', '*', '/', '<', '=', '>', '!',
'?', ':', '$', '%', '_', '&', '~', '^'].includes(char)
);
}
*/Finally, if we find a character that doesn't match any of the known values above, we'll throw a SyntaxError:
default:
// ...
throw new SyntaxError(`Unknown token: ${char}`);Parser
Next, we'll write up the parser.
As discussed earlier, the parser transforms the list of tokens from the scanner into Abstract Syntax Trees (ASTs). To perform this transformation, it uses a specification called the formal grammar of the language. We can express the formal grammar of our Lisp calculator as:
program => expression*
expression => if | call | atom
if => "(" "if" expression expression expression? ")"
call => "(" expression expression* ")"
atom => SYMBOL | NUMBER | BOOLEAN | STRING | ()In longhand:
- A program consists of zero or more expression-s.
- An expression is an if expression, a call expression, or an atom.
- An if expression is an opening bracket, followed by an "if", the test expression, the consequent expression, an optional alternative expression, and a closing bracket.
- A call expression is an opening bracket, followed by the expression to be called, zero or more argument expression-s, and a closing bracket.
- An atom is a symbol, number, boolean, string, or an empty list.
These five rules define how to translate a list of tokens into an AST. A program that does not satisfy the rules has a malformed syntax and is invalid.
The parser we're about to implement is a recursive descent parser. "Descent" implies that we apply the grammar rules starting from the top (the "program") to the bottom (the "atoms"). "Recursive" indicates that we apply the rules recursively; for example, the consequent of an if expression is also an expression.
We'll define a few classes to represent the nodes of the AST:
class Expr {}
class CallExpr extends Expr {
constructor(callee, args) { ... }
}
class SymbolExpr extends Expr {
constructor(token) { this.token = token; }
}
class LiteralExpr extends Expr {
constructor(value) { this.value = value; }
}
class IfExpr extends Expr {
constructor(test, consequent, alternative) { ... }
}In the Parser class, we'll parse the list of tokens as a "program": a set of zero or more expressions.
class Parser {
current = 0;
constructor(tokens) { this.tokens = tokens; }
parse() {
const expressions = [];
while (!this.isAtEnd()) {
const expr = this.expression();
expressions.push(expr);
}
return expressions;
}
isAtEnd() { return this.peek().tokenType === TokenType.Eof; }
peek() { return this.tokens[this.current]; }
}The expression method parses the next expression in the list.
// NULL_VALUE = [];
expression() {
if (this.match(TokenType.LeftBracket)) {
if (this.match(TokenType.RightBracket)) {
return new LiteralExpr(NULL_VALUE);
}
const token = this.peek();
if (token.lexeme === 'if') return this.if();
return this.call();
}
return this.atom();
}
match(tokenType) {
if (this.check(tokenType)) {
this.current++;
return true;
}
return false;
}
check(tokenType) { return this.peek().tokenType === tokenType; }If the current token is not an opening bracket, expression hands over parsing to atom. If it is, it checks the next token. If that token is a closing bracket, it returns a literal expression with a value of null (represented as an empty JavaScript array). But if it is an "if" token, it hands over parsing to the if method. Else, it calls the call method.
In call, we parse the call expression:
call() {
const callee = this.expression();
const args = [];
while (!this.match(TokenType.RightBracket)) {
args.push(this.expression());
}
return new CallExpr(callee, args);
}In if, we parse the conditional expression:
if() {
this.advance(); // move past the "if" token
const test = this.expression();
const consequent = this.expression();
let alternative;
if (!this.match(TokenType.RightBracket)) {
alternative = this.expression();
}
this.consume(TokenType.RightBracket);
return new IfExpr(test, consequent, alternative);
}
consume(tokenType) {
if (this.check(tokenType)) {
return this.advance();
}
throw new SyntaxError(`Unexpected token ${this.previous().tokenType}, expected ${tokenType}`);
}
previous() { return this.tokens[this.current - 1]; }Finally, in atom, we parse the atoms:
atom() {
switch (true) {
case this.match(TokenType.Symbol):
return new SymbolExpr(this.previous());
case this.match(TokenType.Number):
case this.match(TokenType.String):
case this.match(TokenType.Boolean):
return new LiteralExpr(this.previous().literal);
default:
throw new SyntaxError(`Unexpected token: ${this.peek().tokenType}`);
}
}Interpreter
We're now at the core of the interpreter itself, where we evaluate (or interpret) the AST. We'll define an Interpreter class and its environment:
class Interpreter {
constructor() {
this.env = new Map(
Object.entries({
'*': ([a, b]) => a * b,
'+': ([a, b]) => a + b,
'/': ([a, b]) => a / b,
'-': ([a, b]) => a - b,
'=': ([a, b]) => a === b,
remainder: ([a, b]) => a % b,
'>=': ([a, b]) => a >= b,
'<=': ([a, b]) => a <= b,
not: ([arg]) => !arg,
'string-length': ([str]) => str.length,
'string-append': ([a, b]) => a + b,
list: (args) => args,
'null?': ([arg]) => arg === NULL_VALUE,
'list?': ([arg]) => arg instanceof Array,
'number?': ([arg]) => arg instanceof Number,
'procedure?': ([arg]) => arg instanceof Function,
car: ([arg]) => arg[0],
cdr: ([arg]) => (arg.length > 1 ? arg.slice(1) : NULL_VALUE),
cons: ([a, b]) => [a, ...b],
display: ([arg]) => console.log(arg),
})
);
}
}The environment, env, maps a variable name to its value. For now, env only stores the primitive procedures. But we'll extend it to support user-defined variables later on.
We'll add an interpretAll method to interpret the expressions returned by the parser. In interpret, we evaluate a given expression according to its type. Literal expressions evaluate to their values. Symbol expressions evaluate to the value of the variable of the same name.
interpretAll(expressions) {
let result;
for (const expr of expressions) {
result = this.interpret(expr, this.env);
}
return result;
}
interpret(expr, env) {
if (expr instanceof LiteralExpr) {
return expr.value;
}
if (expr instanceof SymbolExpr) {
if (env.has(expr.token.lexeme)) {
return env.get(expr.token.lexeme);
}
throw new RuntimeError(`Unknown identifier: ${name}`);
}
// ...
}Conditional expressions evaluate to the consequent if the test expression is truthy (that is, not #f); else they evaluate to the alternative.
if (expr instanceof IfExpr) {
const test = this.interpret(expr.test, env);
if (test !== false) {
return this.interpret(expr.consequent, env);
}
return this.interpret(expr.alternative, env);
}Finally, call expressions evaluate to the result of calling the procedure with its arguments.
const callee = this.interpret(expr.callee, env);
const args = expr.args.map((arg) => this.interpret(arg, env));
if (callee instanceof Function) {
return callee(args);
}
throw new RuntimeError(`Cannot call ${callee}`);REPL
The implementation for the Lisp calculator is now complete, but we'll need a way to run and test it.
Among its many other legacies, Lisp helped popularize the read-eval-print-loop (REPL), an interactive shell that takes single user inputs, executes them, and then displays the result to the user. We'll add one to our interpreter using Node's repl module.
const repl = require('repl');
repl.start({
prompt: 'jscheme> ',
eval: (input, context, filename, callback) => {
callback(null, stringify(run(input)));
},
});
function stringify(value) {
if (value === false) return '#f';
if (value === true) return '#t';
if (Array.isArray(value)) return '(' + value.map(stringify).join(' ') + ')';
if (value instanceof Function) return 'PrimitiveProcedure';
if (typeof value === 'string') return `"${value}"`;
return String(value);
}We can now run Scheme expressions in the shell and see the printed results:
$ node index.js
jscheme> (+ 34 (car (list 4 3 2 1)))
'38'
jscheme> (string-append "hello, " "world")
'"hello, world"'
jscheme> (if (< (/ 22 7) 3.14) #t #f)
'#f'
jscheme> +
'PrimitiveProcedure'
jscheme> (cons (car (list 7 8 9)) (cdr (list 1 (list 2 3) 4)))
'(7 (2 3) 4)'Global variables
Our interpreter can now evaluate simple expressions. But we'll need a way to create, assign, and access variables. We'll add a define special form for creating global variables and a set! special form for changing the value of a variable.[3]
jscheme> (define x (+ 2 3)) x
'5'
jscheme> (set! x (- 8 1)) x
'7'The parser grammar for the special forms are as follows:
expression => if | call | define | set! | atom
define => "(" "define" SYMBOL expression ")"
set! => "(" "set" SYMBOL expression ")"We'll update the expression method in the parser, and then add methods to parse the new special forms.
expression() {
// ... if (token.lexeme === 'if') ...
if (token.lexeme === 'define') return this.define();
if (token.lexeme === 'set!') return this.set();
// ...
}
define() {
this.advance(); // move past the "define" token
const name = this.consume(TokenType.Symbol);
const value = this.expression();
this.consume(TokenType.RightBracket);
return new DefineExpr(name, value);
}
set() {
this.advance(); // move past the "set!" token
const name = this.consume(TokenType.Symbol);
const value = this.expression();
this.consume(TokenType.RightBracket);
return new SetExpr(name, value);
}
// class DefineExpr extends Expr {
// constructor(name, value) { ... }
// }
// class SetExpr extends Expr {
// constructor(name, value) { ... }
// }Then in the interpreter:
if (expr instanceof DefineExpr) {
const value = this.interpret(expr.value);
env.set(expr.name.lexeme, value);
return;
}
if (expr instanceof SetExpr) {
const value = this.interpret(expr.value);
if (env.has(expr.name.lexeme)) {
env.set(expr.name.lexeme, value);
return;
}
throw new RuntimeError(`Unknown identifier: ${name}`);
}Local variables
To implement scoped variables, we'll add a new special form called let:
jscheme> (define x 1)
jscheme> (let ((x 2) (y 4)) (display x) (display y))
'2'
'4'
jscheme> (display x) (display y)
'1'
Error: Unknown identifier: yThe interpreter needs to be able to access variables in the current scope as well as in "higher", or enclosing, scopes.[4] So, we'll change the environment object from a JavaScript Map to an Environment object.
class Environment {
constructor(params = [], args, enclosing) {
this.values = new Map();
// sets the initial bindings in the environment
params.forEach((param, i) => {
this.values.set(param.lexeme, args[i]);
});
this.enclosing = enclosing;
}
define(name, value) {
this.values.set(name, value);
}
// Sets the variable value in the
// environment where it was defined
set(name, value) {
if (this.values.has(name, value)) {
this.values.set(name, value);
} else if (this.enclosing) {
this.enclosing.set(name, value);
} else {
throw new RuntimeError(`Unknown identifier: ${name}`);
}
}
// Looks up the variable in the environment
// as well as its enclosing environments
get(name) {
if (this.values.has(name)) {
return this.values.get(name);
} else if (this.enclosing) {
return this.enclosing.get(name);
} else {
throw new RuntimeError(`Unknown identifier: ${name}`);
}
}
}As before, we'll update the parser grammar for the let form:
expression => if | call | define | set! | let | atom
let => "(" "let" "(" let-binding* ")" expression* ")"
let-binding => "(" SYMBOL expression ")"Then in the parser:
expression() {
// ...
if (token.lexeme === 'let') return this.let();
// ...
}
let() {
this.advance(); // move past the "let" token
this.consume(TokenType.LeftBracket);
const bindings = [];
while (!this.match(TokenType.RightBracket)) {
bindings.push(this.letBinding());
}
const body = [];
while (!this.match(TokenType.RightBracket)) {
body.push(this.expression());
}
return new LetExpr(bindings, body);
}
letBinding() {
this.consume(TokenType.LeftBracket);
const name = this.consume(TokenType.Symbol);
const value = this.expression();
this.consume(TokenType.RightBracket);
return new LetBindingNode(name, value);
}
// class LetExpr {
// constructor(bindings, body) { ... }
// }
// class LetBindingNode {
// constructor(name, value) { ... }
// }To evaluate a LetExpr-ession, we evaluate the values in its bindings, create a new environment with the current environment as its enclosing environment, and evaluate the body of the expression within the new environment. In the interpreter:
if (expr instanceof LetExpr) {
const names = expr.bindings.map((binding) => binding.name);
const values = expr.bindings.map((binding) => this.interpret(binding.value, env));
const letEnv = new Environment(names, values, env);
let result;
for (const exprInBody of expr.body) {
result = this.interpret(exprInBody, letEnv);
}
return result;
}Lambdas
In this section, we'll add a final construct to the interpreter: the lambda expression.
A lambda in Scheme declares zero or more parameters followed by one or more expressions as its body. When a lambda is called, the interpreter binds its parameters to the passed arguments, evaluates the lambda's body, and returns the result.
Lambdas are also first-class objects in Scheme: they can be assigned to variables, passed as arguments to other lambdas, and so on.
jscheme> (define square
(lambda (n)
(display "square was called")
(* n n)))
jscheme> (square 3)
'"square was called"'
'9'
jscheme> (procedure? square)
'#t'Lambdas also "hang on" to the environment where they are defined (the pair is often called a closure) and can access and modify that environment when called.
jscheme> (define increment-generator
;; returns a lambda that returns the next increment
(lambda ()
(let ((n 0))
(lambda () (set! n (+ n 1)) n))))
jscheme> (define next (increment-generator))
jscheme> (next)
'1'
jscheme> (next)
'2'We'll update the parser grammar for the lambda form:
expression => if | call | define | set! | let | lambda | atom
lambda => "(" "lambda" "(" SYMBOL* ")" expression* ")"Then in the parser:
expression() {
// ...
if (token.lexeme === 'lambda') return this.lambda();
// ...
}
lambda() {
this.advance(); // move past the "lambda" token
this.consume(TokenType.LeftBracket);
const params = [];
while (!this.match(TokenType.RightBracket)) {
params.push(this.consume(TokenType.Symbol));
}
const body = [];
while (!this.match(TokenType.RightBracket)) {
body.push(this.expression());
}
return new LambdaExpr(params, body);
}
// class LambdaExpr extends Expr {
// constructor(params, body) { ... }
// }To evaluate a lambda expression, we return a new Procedure object. The object holds the lambda's declaration and the current environment as its closure. In the interpreter:
interpret(expr, env) {
// ...
if (expr instanceof LambdaExpr) {
return new Procedure(expr, env);
}
// ...
}
// class Procedure {
// constructor(declaration, closure) { ... }
// }Now, to evaluate a call expression (e.g. (proc arg1)), we check to see if the procedure to be called is a Procedure object. Then we run its call method:
// ...
if (expr instanceof CallExpr) {
const callee = this.interpret(expr.callee, env);
const args = expr.args.map((arg) => this.interpret(arg, env));
if (callee instanceof Procedure) {
return callee.call(this, args);
}
// Call primitive procedure
if (callee instanceof Function) {
return callee(args);
}
throw new RuntimeError(`Cannot call ${callee}`);
}
// ...In call, we create a new environment for the lambda call, with the arguments bound to the lambda's parameters and the closure set as the enclosing environment. Then we evaluate the lambda's body and return the result.
class Procedure {
// ...
call(interpreter, args) {
const env = new Environment(this.declaration.params, args, this.closure);
let result;
for (const expr of this.declaration.body) {
result = interpreter.interpret(expr, env);
}
return result;
}
}Tail-call elimination
There's an important optimization we need to make before we declare our interpreter complete.
You may have noticed that we did not implement a loop construct (like a "for" or "while" loop in other languages) in the earlier sections. That's because we don't quite need one: looping in Scheme is done by recursion—and the interpreter already supports that.
jscheme> (define sum-to
(lambda (n acc)
(if (= n 0)
acc
(sum-to (- n 1) (+ n acc))))
jscheme> (sum-to 1 0)
'1'
jscheme> (sum-to 2 0)
'3'
jscheme> (sum-to 3 0)
'6'
jscheme> (sum-to 100 0)
'5050'But because each procedure call calls this.interpret(expr), recursing over a large number of items blows up the call stack of the interpreter.
jscheme> (sum-to 100000 0)
RangeError: Maximum call stack size exceededHowever, since the recursion in sum-to is in tail position (that is, the recursive call is the final expression called by the lambda if n != 0), we can evaluate the call iteratively instead of recursively.
Let's represent the pseudocode for sum-to as follows:
function sum-to(n, acc):
if n = 0 then
return acc
else
return sum-to(n - 1, acc + n)Since the recursive call is in the tail position, we have nothing else to do once sum-to(n - 1, acc + n) completes. We immediately return its result.
For this reason, instead of recursing and allocating a new stack frame, we can "hand over" the function body to the new call. Instead of recursively calling sum-to, we'll update the function's arguments and jump back to the top of the function's body.
function sum-to(n, acc):
start:
if n = 0 then
return acc
else
n = n - 1
acc = acc + n
GOTO startWe'll add this tail-call optimization to our Scheme interpreter. When evaluating a procedure call in the tail position, the interpreter will update the current frame and make a GOTO-like jump to the top of the interpret method instead of recursing.[5]
Let's review how we currently interpret call expressions:
interpret(expr, env) {
if (expr instanceof CallExpr) {
const callee = this.interpret(expr.callee, env);
const args = expr.args.map((arg) => this.interpret(arg, env));
if (callee instanceof Procedure) {
const callEnv = new Environment(callee.declaration.params, args, this.closure);
// Recursively interpret all the expressions
// in the function body within `callEnv`
let result;
for (const exprInBody of callee.declaration.body) {
result = this.interpret(exprInBody, callEnv);
}
return result;
}
// ...
}
// ...
}Instead of recursively interpreting all the expressions in the procedure's body, when we get to the last expression, we want to update the frame of the interpret method and "jump" back to the top.
interpret(expr, env) {
startInterpret:
if (expr instanceof CallExpr) {
// ...
if (callee instanceof Procedure) {
// ...
const callBody = callee.declaration.body;
// Recursively interpret all expressions in the body *except the last*
for (const exprInBody of callBody.slice(0, -1)) {
this.interpret(exprInBody, callEnv);
}
// For the last expression, update expr
// and env and jump back to the top ↑↑
expr = callBody[callBody.length - 1];
env = callEnv;
GOTO startInterpret;
}
// ...
}
// ...
}JavaScript doesn't have a GOTO statement. So we'll use the next best thing: we'll place the entire body of the interpret method inside a while loop and then continue the loop to jump back to the top.
interpret(expr, env) {
while (true) {
if (expr instanceof CallExpr) {
// ...
if (callee instanceof Procedure) {
// ...
for (const expr of callBody.slice(0, -1)) {
this.interpret(expr, callEnv);
}
expr = callBody[callBody.length - 1];
env = callEnv;
continue;
}
// ...
}
// ...
}
}The continue statement effectively jumps back to the top of the method and evaluates the tail expression with its correct environment without recursing. Now, we can call tail-recursive functions with large inputs without overflowing the call stack!
jscheme> (sum-to 10000 0)
50005000We may also add this same optimization in the other places where we evaluate tail expressions, like when interpreting let and if expressions.
interpret(expr, env) {
while (true) {
// ...
if (expr instanceof IfExpr) {
const test = this.interpret(expr.test, env);
// Instead of calling this.interpret() on the consequent or alternative, update the expr argument and continue the loop
expr = test !== false ? expr.consequent : expr.alternative;
continue;
}
if (expr instanceof LetExpr) {
const letEnv = new Environment(names, values, env);
// Recursively interpret all the expression in the body *except the last one*
for (const exprInBody of expr.body.slice(0, -1)) {
this.interpret(exprInBody, letEnv);
}
// for the tail expression, update expr
// and env and continue the loop
expr = expr.body[expr.body.length - 1];
env = letEnv;
continue;
}
// ...
}
}Our Scheme interpreter is still far from complete. It lacks comments, ports, vectors, call-with-current-continuation, dotted pair notation, quotes and quasi-quotes, many primitive procedures, comprehensive error detection and recovery, and more. But it implements many of the core features of Scheme. And hopefully, it has given a decent insight into some of the inner workings of interpreters. We can take a victory lap here.
The complete source code is available on GitHub.
This essay is largely inspired by Peter Norvig's (How to Write a (Lisp) Interpreter (in Python)). ↩︎
Tokens typically also store metadata like the line and column numbers on which they appear in the source, useful for error reporting and debugging. But I've left them out of this implementation for clarity. ↩︎
Note why
defineandset!are both special forms. Non-special-form procedures evaluate all their arguments before using them. Butdefineandset!cannot be evaluated that way since they cannot evaluate their first argument, the identifier name. ↩︎In Pointers in Go, I wrote briefly about how this linked-list implementation of environments is used in the Lox interpreter from Bob Nystrom's Crafting Interpreters. ↩︎
Other ways to implement tail-call elimination include writing a VM and using trampolines. But both methods are much more involved than using
continueand far beyond the scope of this essay. See the Wikipedia entry on tail-call implementation methods or Eli Bendersky's essay on recursion, continuations, and trampolines. ↩︎