Quadtrees in the Wild
Choosing good data structures and algorithms can have a significant impact on the performance of a program. Some data structures store information faster (but retrieve the information slower) than other data structures. And, for the same operation, one algorithm can perform faster on average (but slower in important edge cases) than another algorithm.
And so, learning about the performance benefits and tradeoffs of using different data structures and algorithms can help us write programs that solve problems more effectively.
Starting with this post, I'll be writing a series called Data Structures and Algorithms in the Wild. Throughout the series, we'll review a few different data structures and algorithms to see how they work and what kinds of problems they solve.
We'll start with a data structure called the quadtree and explore its applications in spatial indexing and image compression.
Why we use quadtrees
Quadtrees are tree structures used to efficiently store data in two-dimensional space.
Say we have an app that shows a user the locations of grocery stores close to them. A store signs up by submitting its location. And when a user opens the app, they see all the stores within a certain distance from their current location. Given the locations of all the stores, can we write a program that returns all the points within a boundary?
One quick solution could be to keep all the store locations in a list of (x, y) points. To find the points within a boundary, we loop over the list and return all the points that fall within the boundary.
function insert(points, point) {
points.push(point);
}
function search(points, boundary) {
return points.filter((point) => contains(boundary, point));
}
// Returns true if point falls within boundary
function contains(boundary, point) {
return (
point.x >= boundary.x1 &&
point.x <= boundary.x2 &&
point.y >= boundary.y1 &&
point.y <= boundary.y2
);
}
const points = [];
insert(points, { x: 1, y: 5 });
insert(points, { x: 2, y: 1 });
insert(points, { x: 3, y: 6 });
search(points, { x1: 0, y1: 2, x2: 4, y2: 8 });
// [{ x: 1, y: 5 }, { x: 3, y: 6 }]
This search function has a runtime complexity of O(n). Because we loop through all the points, the time it takes to find points within a boundary increases linearly with the total number of points.
But what if we split up the space into sections? This way, we only need to search the sections that intersect with the search boundary, and we can ignore the other sections.
This is essentially how quadtrees work. We start by adding points to the root node of the quadtree, which defines the entire possible space. When the number of points in the node reaches a predefined maximum capacity, it splits into four child nodes (four quadrants). And when any of those nodes reaches the maximum capacity of points, it splits again into four child nodes, and so on.
Points within a boundary
To insert a point into a quadtree, we first check if the node has enough capacity to receive the point. If it does, we save the point in that node. But if it doesn't, we split the node into four quadrants and then insert the point into the quadrant where it falls.
function insert(node, point) {
// If the point is outside the node's boundary, return false
if (!contains(node.boundary, point)) {
return false;
}
// If this node has not yet reached its capacity and has not
// yet been subdivided, insert the point into this node
if (node.points.length < NODE_CAPACITY && !node.isSubdivided()) {
node.points.push(point);
return true;
}
// At this point, the node has either already been subdivided,
// or has reached its capacity but hasn't been subdivided
// If the node has reached its capacity,
// but hasn't been subdivided, subdivide
if (!node.isSubdivided()) {
subdivide(node);
}
// Insert the point into its correct child node. We can try inserting
// into all the child nodes. The wrong ones (where the point's position
// is outside the child node's boundary) would simply return false,
// until we find the correct child node.
if (insert(node.topLeftChild, point)) return true;
if (insert(node.bottomLeftChild, point)) return true;
if (insert(node.topRightChild, point)) return true;
if (insert(node.bottomRightChild, point)) return true;
// We shouldn't ever get to this point, though
return false;
}
const quadtree = { boundary: { x1: 0, y1: 0, x2: 8, y2: 8 }, points: [] };
insert(quadtree, { x: 1, y: 1 });
insert(quadtree, { x: 3, y: 7 });
To subdivide a node into its child nodes, we split the node's area into four quadrants. Then, we add the existing points in the node into the correct child node.
function subdivide(node) {
// Create the four child nodes
const { x1, x2, y1, y2 } = node.boundary;
const midX = (x1 + x2) / 2;
const midY = (y1 + y2) / 2;
node.topLeftChild = createNode({ x1, y1, x2: midX, y2: midY });
node.bottomLeftChild = createNode({ x1, y1: midY, x2: midX, y2 });
node.topRightChild = createNode({ x1: midX, y1, x2, y2: midY });
node.bottomRightChild = createNode({ x1: midX, y1: midY, x2, y2 });
// Move the points in the node to the child node that should contain the point.
// Again, we can try inserting each point into all the child nodes. The wrong ones
// (where the point's position is outside the child node's boundary) would simply
// return false, until we find the correct child node.
node.points.forEach((point) => {
if (insert(node.topLeftChild, point)) return;
if (insert(node.bottomLeftChild, point)) return;
if (insert(node.topRightChild, point)) return;
if (insert(node.bottomRightChild, point)) return;
});
node.points = [];
}
function createNode(boundary) {
return { boundary, points: [] };
}
Now, we can write the search function. Given a boundary, the function will check the nodes that intersect with the boundary and return the points in those nodes that fall within the boundary.
function search(node, boundary) {
// If this node does not intersect with the search boundary, we know that
// the node and all its child nodes do not contain any points that fall
// into the search boundary
if (!intersects(node.boundary, boundary)) {
return [];
}
// If this node has not yet been subdivided, return
// all the points within the search boundary
if (!node.isSubdivided()) {
return node.points.filter((point) => contains(boundary, point));
}
// If the node has been subdivided, search all
// the child nodes and merge the results
return search(node.topLeftChild, boundary)
.concat(search(node.bottomLeftChild, boundary))
.concat(search(node.topRightChild, boundary))
.concat(search(node.bottomRightChild, boundary));
}
// Returns true if two boundaries intersect
function intersects(b1, b2) {
return b1.x1 <= b2.x2 && b1.x2 >= b2.x1 && b1.y1 <= b2.y2 && b1.y2 >= b2.y1;
}
const quadtree = { boundary: { x1: 0, x2: 8, y1: 0, y2: 8 }, points: [] };
insert(quadtree, { x: 1, y: 1 });
insert(quadtree, { x: 2, y: 2 });
insert(quadtree, { x: 4, y: 4 });
insert(quadtree, { x: 6, y: 6 });
insert(quadtree, { x: 3, y: 7 });
search(quadtree, { x1: 3, y1: 3, x2: 7, y2: 7 });
// [{ x: 4, y: 4 }, { x: 6, y: 6 }, { x: 3, y: 7 }]
At each node, we first check to see if the node's boundary intersects with the search boundary. If it doesn't, we can skip the node and all its child nodes. This saves us from wasting time looping through points we already know do not fall inside the search boundary.
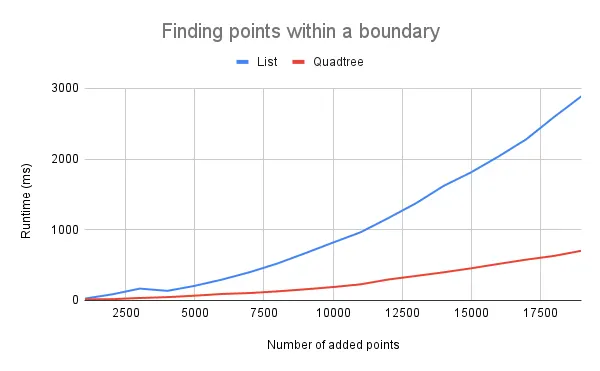
Consequently, quadtrees perform best when the data points are fairly evenly scattered. If most of the points are positioned close to one another, the quadtree becomes unbalanced. Only a few nodes would hold most of the points, and the runtime performance of searching the quadtree will tend closer towards that of the list.1
Nearest point to a location
Returning to our store finder app, what if we wanted to show the user the nearest store to them? If we store the points in a list, it takes linear time to perform this task.
function nearest(points, location) {
let nearestPoint;
let nearestPointDistance = Number.MAX_VALUE;
points.forEach((point) => {
const dist = distance(point, location);
if (dist < nearestPointDistance) {
nearestPoint = point;
nearestPointDistance = dist;
}
});
return nearestPoint;
}
// Returns the Euclidean distance between two points
function distance(p1, p2) {
return Math.sqrt(Math.pow(p1.x - p2.x, 2) + Math.pow(p1.y - p2.y, 2));
}
Alternatively, with a quadtree, we can check the smallest quadrant which surrounds the search location first. This node would likely have points that are very close to the search location. Then, when we check through the rest of the tree, we can exclude quadrants that are too far away without even checking their child quadrants and points.2
We follow a few steps:
- At each node of the quadtree, we check to see if the node has been subdivided.
- If it has, we recursively check its child nodes. Importantly, we'll check the child node that contains the search location first, before checking the other child nodes.3
- When we get to a node that has not been subdivided, we'll loop through all its points and return the point nearest to the search location.
- As we recurse back up the tree, when we get to a node that is farther away than the nearest point we've found, we can safely discard that quadrant without checking its child quadrants or points.
function nearest(node, location, nearestPoint) {
// If this node is farther away than the nearest point we've
// found so far, no need to check here or any of its child nodes
if (distanceToBoundary(location, node.boundary) > nearestPoint.distance) {
return nearestPoint;
}
// Not yet subdivided, return the nearest point in this node
if (!node.isSubdivided()) {
node.points.forEach((point) => {
const dist = distance(point, location);
if (dist < nearestPoint.distance) {
nearestPoint.point = point;
nearestPoint.distance = dist;
}
});
return nearestPoint;
}
// Since this node has already been subdivided, check all its child nodes.
// Check the child node where the location falls first, before checking
// the adjacent nodes, and then the opposite node.
// (See the notes at the end of the post for a more detailed explanation)
const childNodes = [
node.topLeftChild,
node.topRightChild,
node.bottomLeftChild,
node.bottomRightChild,
];
// true if location is at the top half
const tb = location.y < (node.boundary.y1 + node.boundary.y2) / 2;
// true if location is at the left half
const lr = location.x < (node.boundary.x1 + node.boundary.x2) / 2;
const containingNode = childNodes[2 * (1 - tb) + 1 * (1 - lr)];
const adjacentNode1 = childNodes[2 * (1 - tb) + 1 * lr];
const adjacentNode2 = childNodes[2 * tb + 1 * (1 - lr)];
const oppositeNode = childNodes[2 * tb + 1 * lr];
nearestPoint = nearest(containingNode, location, nearestPoint);
nearestPoint = nearest(adjacentNode1, location, nearestPoint);
nearestPoint = nearest(adjacentNode2, location, nearestPoint);
nearestPoint = nearest(oppositeNode, location, nearestPoint);
return nearestPoint;
}
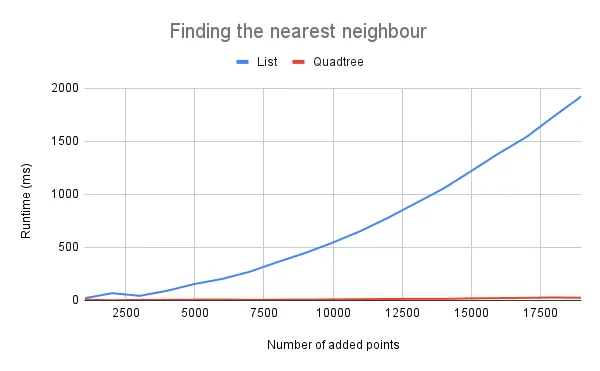
Image compression
Quadtrees can also be used to compress pictures. The algorithm works in three steps:
- Split up the image into four quadrants.
- Calculate the amount of error in each quadrant. First, calculate the average colour in the quadrant. Then, for each pixel in the quadrant, calculate the difference between the pixel's colour and the average colour. The average of all the differences will be the error in the quadrant.
- If the error in a quadrant exceeds some predefined maximum value, split the quadrant into four child quadrants and repeat step 2.
At the end of the process, each quadtree node will contain the average colour (within the specified error limit) of some section of the compressed image.4
Converting this into code:
function compress(pixels, w, h, node) {
const avg = average(pixels, w, h);
const err = error(pixels, w, h, avg);
// If the node has less than the maximum allowed error,
// store the color and error values in the node
if (err < MAX_ERROR) {
node.color = avg;
return;
}
// If the node has more than the maximum allowed error,
// split the node into child nodes and compress each child node
const { x1, x2, y1, y2 } = node.boundary;
const midX = Math.floor((x1 + x2) / 2);
const midY = Math.floor((y1 + y2) / 2);
node.children = [
createNode({ x1: x1, y1: y1, x2: midX, y2: midY }), // Top-left
createNode({ x1: x1, y1: midY + 1, x2: midX, y2: y2 }), // Bottom-left
createNode({ x1: midX + 1, y1: y1, x2: x2, y2: midY }), // Top-right
createNode({ x1: midX + 1, y1: midY + 1, x2: x2, y2: y2 }), // Bottom-right
];
// ...then compress each of the child nodes
node.children.forEach((child) => {
const startx = child.boundary.x1 - x1;
const endx = child.boundary.x2 - x1;
const starty = child.boundary.y1 - y1;
const endy = child.boundary.y2 - y1;
const childPixels = slice2d(pixels, startx, endx, starty, endy);
const childW = midX - x1;
const childH = midY - y1;
compress(childPixels, childW, childH, child);
});
}
// Compressing a 128px-by-128px image
const pixels = [[{ r: 125, g: 73, b: 209 }, ...], ...];
const w = (h = 128);
const quadtree = { boundary: { x1: 0, y1: 0, x2: w - 1, y2: h - 1 } };
compress(pixels, w, h, quadtree);
To display the compressed image, we draw the colours in each leaf node of the tree.
function drawTree(tree, width, height) {
canvas.width = width;
canvas.height = height;
const ctx = canvas.getContext("2d");
drawNode(tree, ctx);
}
function drawNode(node, ctx) {
if (!node.children) {
const { r, g, b } = node.color;
ctx.fillStyle = `rgb(${r},${g},${b})`;
const { x1, x2, y1, y2 } = node.boundary;
ctx.fillRect(x1, y1, x2 - x1 + 1, y2 - y1 + 1);
return;
}
node.children.forEach((child) => {
drawNode(child, ctx);
});
}
drawTree(quadtree, w, h);
By varying the maximum amount of error in each quadrant, we can change the amount of compression done to the image:
The complete code for the examples in this post is available on GitHub.
Footnotes
-
In the worst-case scenario (when the quadtree is unbalanced or when the search boundary covers the entire space), searching through the quadtree has a linear time complexity.
But in the best case (when the points are evenly distributed across the nodes and the search boundary is small), searching the quadtree takes O(log4(n)) time.
If we have 4 (or fewer) points in the tree, the tree would have only its root node.
If we have 16 evenly distributed points, the tree would have its root node and 4 leaf nodes, each holding 4 points. If the search boundary only covers a small area (only intersects with one leaf node), searching through the tree would take twice as long as before: check the root node, check the child node, then check the points in the child node in constant time. (Checking the points within a node takes constant time because we know a node can only hold a maximum of 4 points.)
Similarly, if we have 64 evenly distributed points, the tree would have its root node with 4 child nodes, each also having 4 child nodes. In other words, the tree would have a depth of 3, with 16 leaf nodes each holding 4 points. Again, if the search boundary only intersects with one leaf node, searching through the tree would take three times as long as the first time: check the root node, check the child node, check the grand-child node, then check the points in the grand-child node in constant time.
The time it takes to search the tree grows in proportion to the base-4 logarithm of the number of points in the tree: 4 points -> 1x, 16 -> 2x, 64 -> 3x, etc. So, we say that the search algorithm (in this best-case scenario) has a runtime complexity of O(log4(n)). ↩
-
Adapted from Patrick Surry's D3JS quadtree nearest neighbor algorithm ↩
-
What we're trying to do here is to sort the child nodes by their closeness to the search location. We can use a simple heuristic: the node where the point falls (the containing node) is closest, followed by the adjacent nodes, and the farthest is the opposite node.
For example, if the search location falls on the bottom-left corner, the bottom-left node is closest, followed by the top-left and bottom-right nodes, and last, the top-right node.
First, we check what position the search location is in:
const tb = location.y < (node.boundary.y1 + node.boundary.y2) / 2; const lr = location.x < (node.boundary.x1 + node.boundary.x2) / 2;These two booleans (
tb-lr) tell us whether the search location is at the top-left (true-true), top-right (true-false), bottom-left (false-true), or bottom-right (false-false) corner.Then, we can create a list of the child nodes from left to right and top to bottom.
const childNodes = [ node.topLeftChild, node.topRightChild, node.bottomLeftChild, node.bottomRightChild, ];We can see that, given a value of
tbandlr, the containing node will be at the array index equivalent to flipping both booleans. For example, if the search location is at the top-left corner, (tb= true,lr= true), the containing node will be at index00(0in decimal) in thechildNodesarray. The adjacent nodes will be at the indexes equivalent to flipping one boolean:01(1in decimal) and10(2in decimal). And the opposite node will be at the index equivalent to flipping no booleans: index11(3in decimal).Similarly, if the search location is at the bottom-left corner, (
tb= false,lr= true), the containing node will be at index10(2in decimal). The adjacent nodes will be at indexes00(0in decimal) and11(3in decimal). And the opposite node will be at index01(1in decimal). The same works for any combination oftbandlr.const containingNode = childNodes[2 * (1 - tb) + 1 * (1 - lr)]; const adjacentNode1 = childNodes[2 * (1 - tb) + 1 * lr]; const adjacentNode2 = childNodes[2 * tb + 1 * (1 - lr)]; const oppositeNode = childNodes[2 * tb + 1 * lr]; -
This type of quadtree, where each node covers a region and a data value, is called a region quadtree. The quadtree we used in the first two quadrants is a point-region (PR) quadtree. A point-region quadtree is similar to a region quadtree, but each region holds items up to a predefined capacity before splitting. ↩